Die zuvor vorgestellte MatterPT ist ein sehr einfaches Sprachmodell. Sie schaut immer nur ein einziges Wort zurück und basiert auf einem einzelnen Liedtext. Dadurch kann sie zwar Wortfolgen nachahmen, „versteht“ den Inhalt aber kaum.
Die im Internet verfügbare Lernumgebung Soekia.gpt ist bereits weiterentwickelt. Sie bezieht bis zu fünf vorhergehenden Worten ein und wurde mit etwa 20 verschiedenen Texten trainiert. So kann sie den Zusammenhang innerhalb eines Satzes besser erfassen und erzeugt Texte, die bereits etwas natürlicher wirken.
Trotzdem bleibt auch Soekia.gpt ein vereinfachtes – didaktisches – Sprachmodell. Es arbeitet ausschliesslich mit statistischen Wahrscheinlichkeiten und verfügt über kein inhaltliches oder konzeptuelles Verständnis.
Analog funktionieren grosse Sprachmodelle, sogenannte Large Language Models (LLMs) wie GPT. Sie werden mit sehr grossen Textsammlungen trainiert, zum Beispiel aus Wikipedia, Büchern, Zeitungsartikeln und wissenschaftlichen Texten oder sonstigen menschengeschriebenen oder von Menschen kuratierten Texten.
Statt nur einzelne Wörter zu vergleichen, können sie sehr viele Wortbestandteile (Tokens) gleichzeitig berücksichtigen – oft mehrere Tausend auf einmal. In erweiterten Versionen (z.B. 5.3 – Stand 03.2036) kann ChatGPT zum Beispiel bis zu 128 000 Tokens in einem einzigen Kontext verarbeiten (OpenAI, 2026). Gemini, die LLM von Google kann sogar bis zu 1. Million Tokens im Kontext verarbeiten (Georgiev et al., 2024)
Konkret kann das heissen, dass verschiedene Begriffe mathematisch zueinander in Beziehung gesetzt werden, um so eine möglichst plausible Wortfolge in der Antwort zu erhalten:
So können die Sprachmodelle Bedeutungen, Satzbau und inhaltliche Zusammenhänge mathematisch erfassen. Eine Möglichkeit, wie das funktionieren kann, ist die Vektorisierung von Beziehungen, veranschaulicht an der folgenden Darstellung:
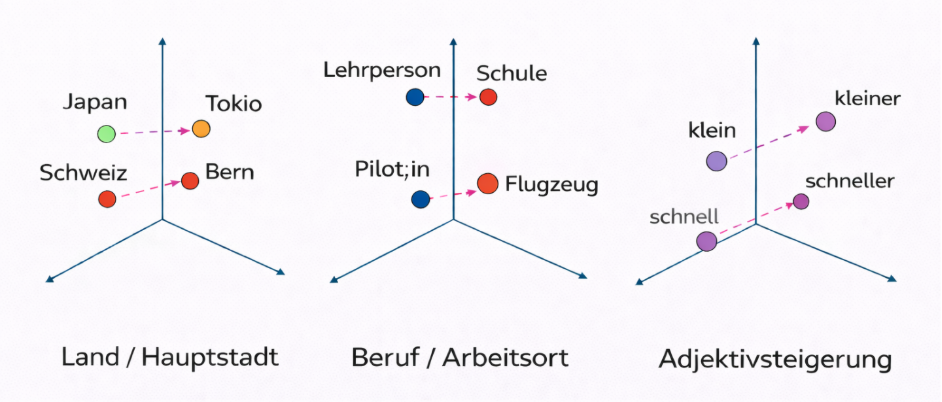
Die Modelle erscheinen dadurch in der Lage, längere Texte zu verstehen, logische Bezüge herzustellen und sogar Stimmungen oder Absichten erkennen zu können, wobei dieses Verständnis rein mathematischer Art und nicht mit inhaltlichem Verständnis gleichzusetzen ist.
Möglich wird dies durch die enorme Rechenleistung moderner Rechenzentren. Sie erlauben das Training von Modellen mit Milliarden von Parametern, also vielen einstellbaren „Stellschrauben“. Das Ergebnis ist ein Sprachmodell, das weit mehr kann, als nur wahrscheinliche Wortfolgen aneinanderzureihen.

Abbildung 1: Rechenzentrum von Amazon (https://www.tagesanzeiger.ch/google-microsoft-und-amazon-ki-boom-versaut-klimabilanz-501159207456)
Die Funktionsweise generativer Bild oder Video Ki ist derjenigen der LLM sehr ähnlich. Anstatt Wörter werden einfach einzelne Pixesl zueinander in Beziehung gesetzt.
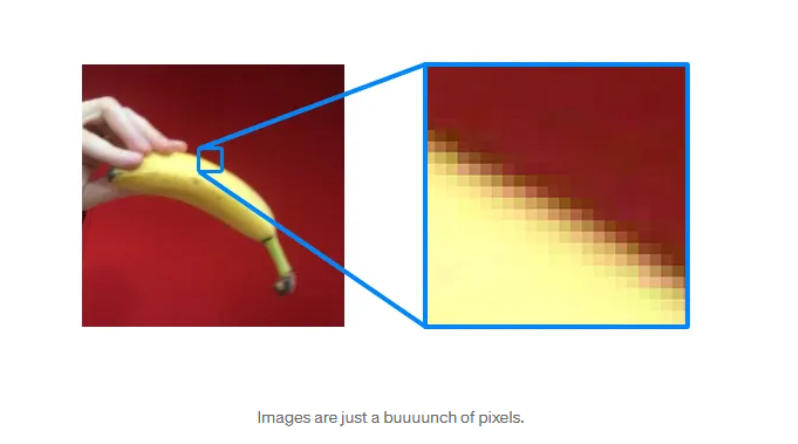
Abbildung 2:(Webster, 2019)
Praxisaufgabe: Soekia.GPT
Gehe zu den Trainingsdaten und tippe gezielt und an mehreren Stellen Falschinformationen rein. Beobachte nun die Veränderung auf den Output
Einfach
- Öffne die vortrainierte Märchen PT SoekiaGPT – Das didaktische Sprachmodell (Wortvorhersage auf der Grundlage von 14 bekannter Märchen). Gib den Befehl „Schreib mir ein Märchen“ ein und lass dich überraschen.
- Verändere nun die „Feinheit“ der Antwort, in dem du auf das rote Zahnrad klickst. Verändere die Temperatur etc.
- Auflösung: Die Temperatur (Stärker der Zufallskomponente, ‘Kreativität’) steht für die Abweichung in der Wortwahl- Mit höherer Temperatur wirst du festgestallt haben, dass deine Texte der Range der verwendetetn Wörter angestiegen ist, jeodch inhaltlich auch nicht Sinnzussammenhöngen eTexte enstanden sind.
- Wähle 1-2 Märchen aus und passe einzeln Wörter so an, dass der Inhalt verfälscht wird. Beobachte nun die Veränderung auf den Output.
- Ergänze im grünen Feld weitere Märchen.
Mittel
- Baue deine eigene Songkollektion: Füge Songtexte von deinem Lieblingsinterpreten hinzu und kreiere weitere Songs.